如何不停服迁移数据
数据迁移案例分析
文章地址: https://blog.piaoruiqing.com/blog/2019/10/27/不停服怎么迁移数据/
前言
数据迁移时, 为了保证数据的一致性, 往往伴随着停服, 此期间无法给用户提供服务或只能提供部分服务. 同时, 为了确保迁移后业务及数据的正确性, 迁移后测试工作也要占用不少时间. 如此造成的损失是比较大的.
接下来, 本文将就如何在不停服的情况下进行数据迁移进行探讨.
案例
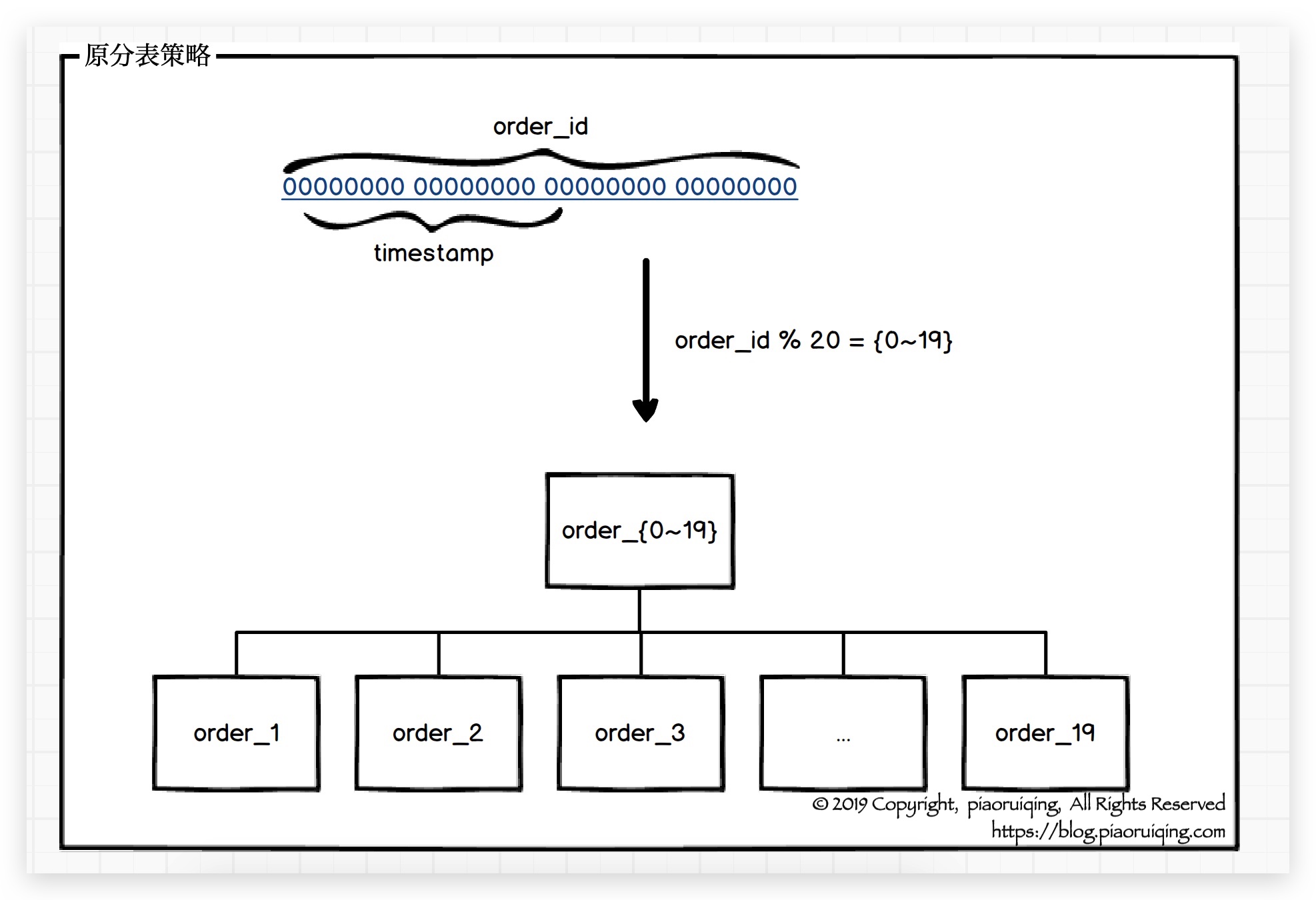
订单系统中存在这样一组订单表:
数据库: MySQL
表名: order_{0
19}, 其中{019}为后缀, 合共20张表.主键: order_id, 订单ID, 通过雪花算法获得, 可通过ID获取创建时间.
原分表策略: order_id % 20
伴随着业务量增长, 各分表的数据量已经破千万, 如此下去会产生严重的性能问题, 此时需要将原分表进行迁移.
要求:
- 将原20张分表数据迁移至新表
- 迁移全过程中不可停机, 须对外提供完整的服务.
- 提供完备的回退方案, 迁移过程中产生的数据不可丢, 不能人为修数据.
分析
有过分库分表经验的读者可能已经发现案例中原分表策略十分不合理, 其缘由不去追究(毕竟换了几波人之后已经没办法找到当年的人吊起来揍了).
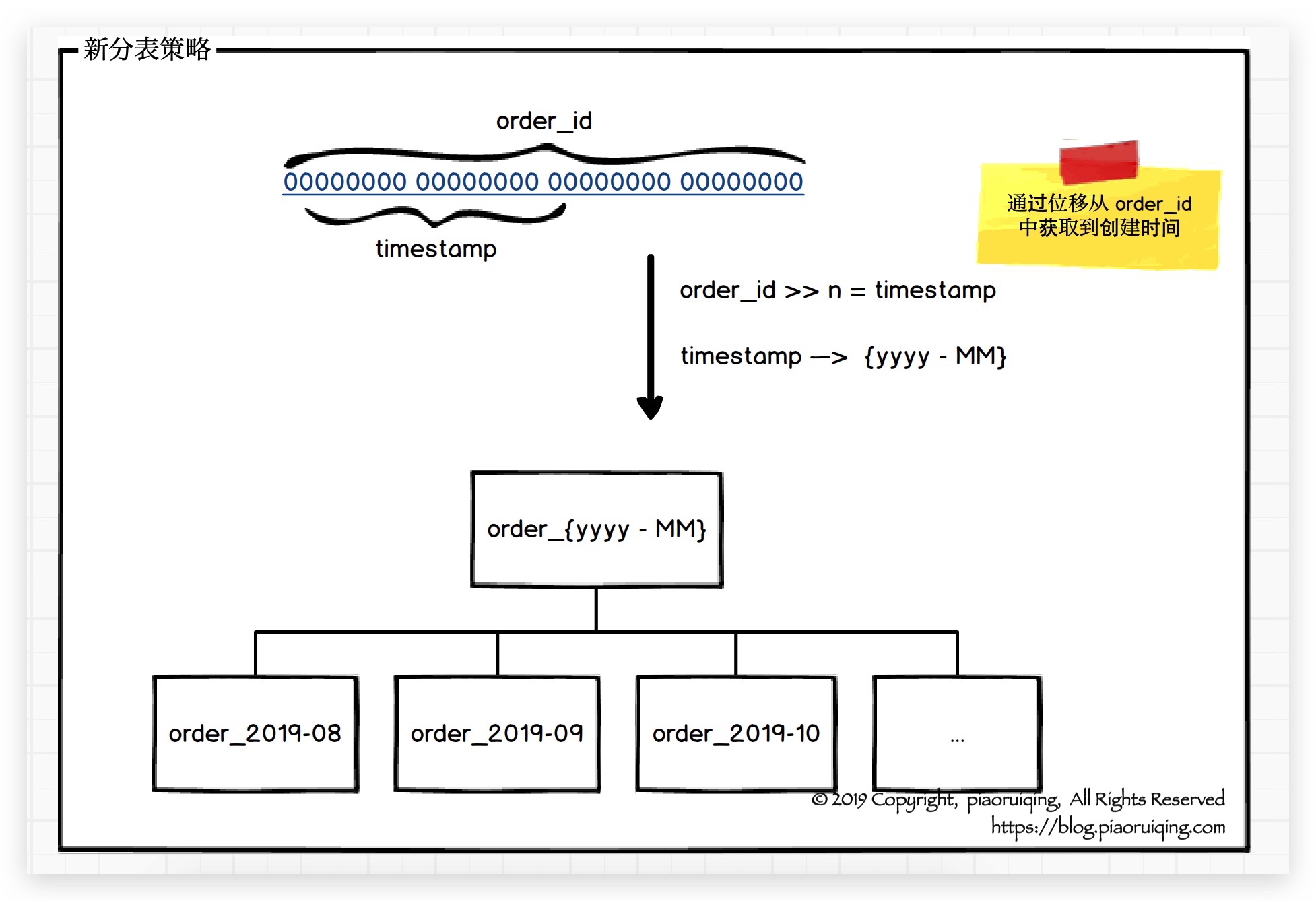
分析一下原数据表: 订单数据肯定会伴随着时间和业务量直线上升, 固定的分表数量会导致随数据量增大性能下降. 所以, 数据迁移后, 分表的数量不能再固定, 即使从20改成100个总有一天也会达到瓶颈.
订单数据会伴随时间增长, 而且在超过退款期限后就变成了冷数据, 使用率会降低. 因此, 将订单按照创建时间来进行分表是一个不错的选择. 值得一提的是, order_id是通过雪花算法获得, 可以从order_id中获取创建时间, 可以通过order_id直接获取分片键.
迁移方案分析
数据迁移的方案从业务层到数据库层各有不同的迁移方案, 我们先列举一些进行比对:
业务层: 在业务层进行硬编码, 数据双写, 以某个时间点进行划分, 新产生的数据同时写入新表, 运行一段时间后将旧数据迁移至新表. 成本极高, 与业务耦合严重, 不考虑.
连接层: 是方案1的进阶版, 在连接层拦截SQL进行双写, 与业务解耦, 但与1有着同样的一个问题: 周期较长, 要确保旧数据不会产生变更才能进行迁移.
触发器: 通过触发器将新产生的数据同步到新表, 本质上与2差不多.
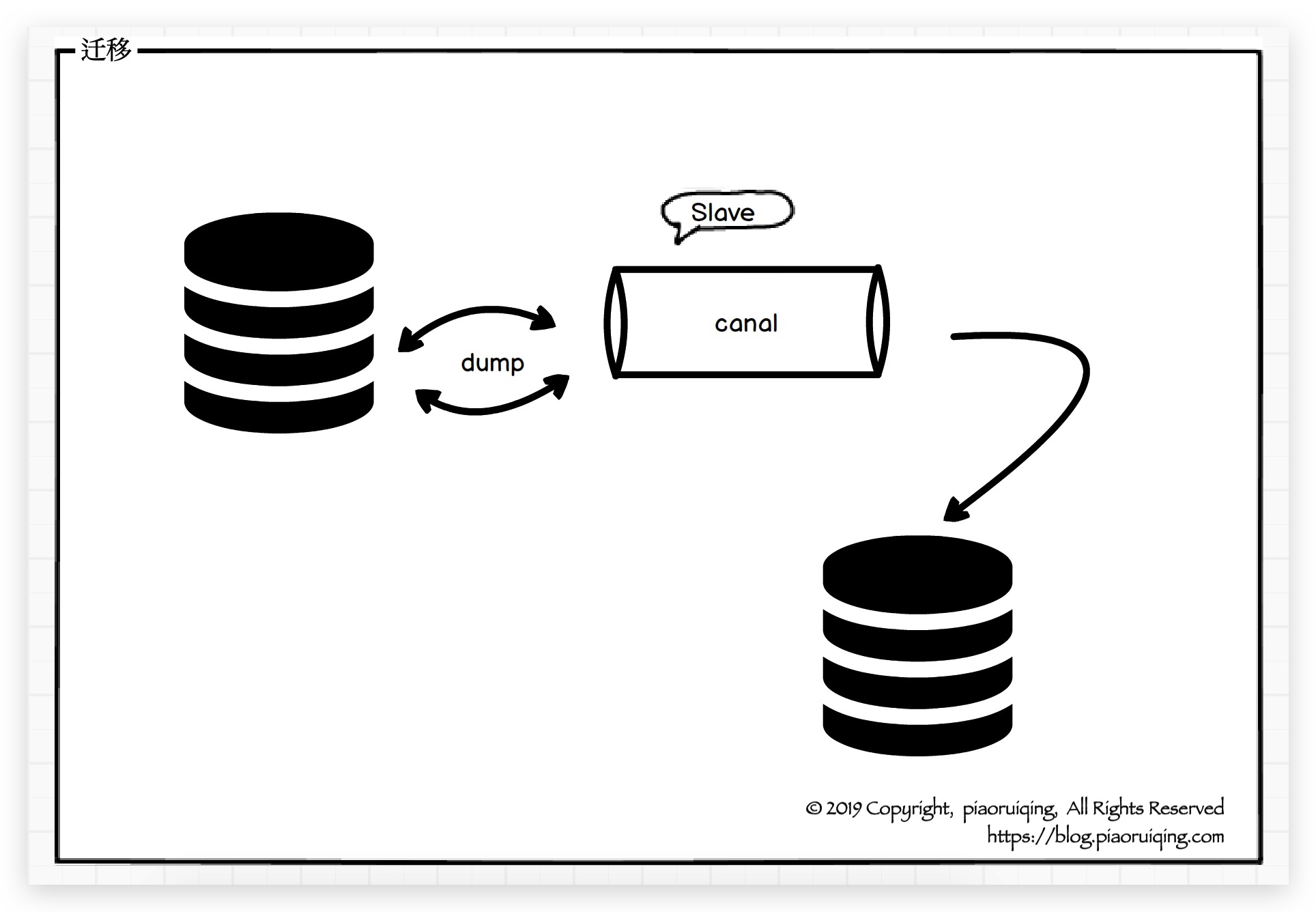
数据库日志: 从某一时间点T备份数据库, 将备份库的数据迁移至新表, 从时间点T读取日志, 恢复到新表, 并持续写入. 待两份数据保持同步后, 上线新代码.
伪装从库: 相对于方案4的优势是不需要直接去读取日志, 解决了数据库在云上不方便直接读取日志的问题.
相比较之下, 方案4和5都是可选的, 因数据库在云上, 直接读取日志不方便, 且方案5有成熟的开源中间件canal可用, 故笔者选择了方案5.
Canal文档地址: https://github.com/alibaba/canal/wiki
本文发布于朴瑞卿的博客, 允许非商业用途转载, 但转载必须保留原作者朴瑞卿 及链接:http://blog.piaoruiqing.com. 如有授权方面的协商或合作, 请联系邮箱: piaoruiqing@gmail.com.
回退方案分析
新代码上线后, 谁也不能确保百分百没问题. 若迁移失败, 必须要进行回滚. 所以, 需要保证原数据和新数据的同步.
所以, 在前一小节方案5的基础上, 切流量到新集群后, 我们停止数据同步, 从切流量时刻开始同步新表数据到旧表, 方案也是伪装从库. 如此就能保证新旧表的数据同步, 如果上线后发生了异常, 将流量切回旧集群即可.
整体方案设计
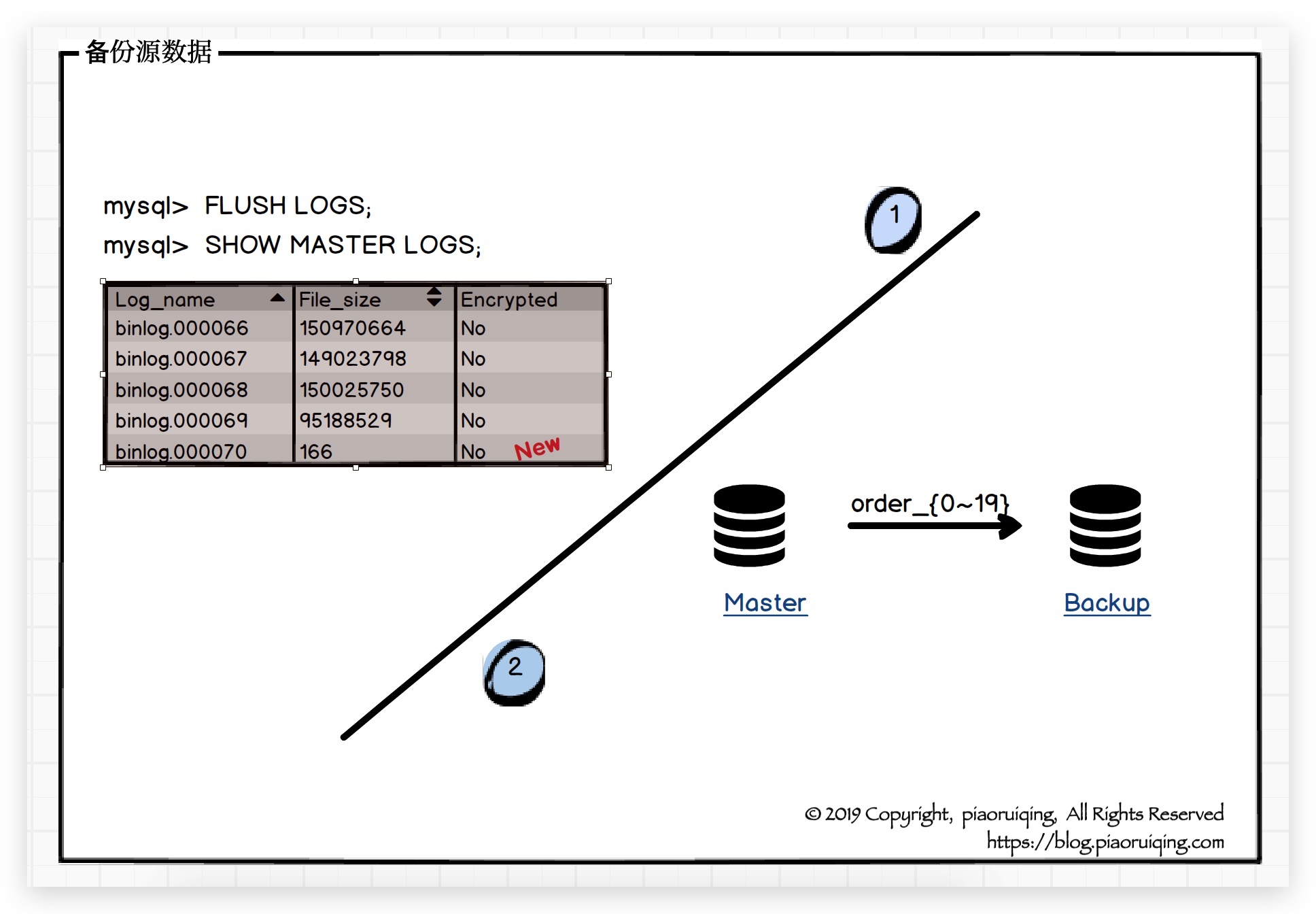
备份源数据
- 执行
flush logs: 生成新的binlog, 恢复数据将从这里开始. - 备份数据表(order_{0~19}): 将源(旧)数据表从主库A复制到备份库B
恢复并同步数据
- 在主库A创建足够的新表, order新表按照月进行分表.
- 写脚本读取备份库B中的order表, 写入主库A的order新表.
- 通过canal开始同步旧表数据到新表, 命名为[同步过程-a].
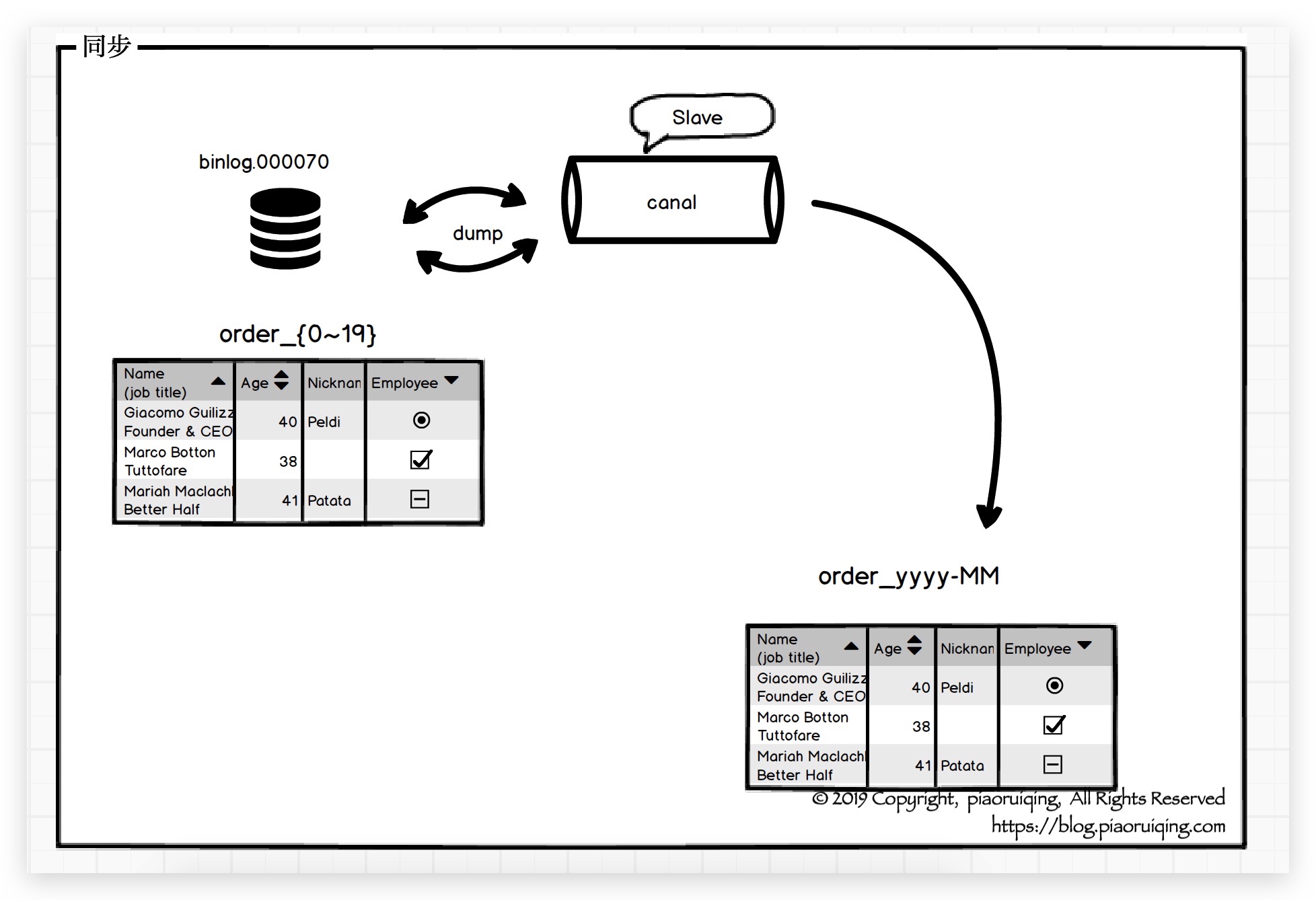
上线
- 编译新代码并弹一个新的集群, 确认完全启动完成.
- 执行
flush logs生成新的binlog, 新表向旧表同步数据将从这里开始. - 流量切到新集群.
- 停止[同步过程-a].
- 开始从新表向旧表同步数据.
回退
上线后应及时进行测试, 一旦发现严重的异常就立即将流量切回旧集群.
结语
flash logs要先于备份源数据表, 即使中间有些许时间间隔也不会影响数据的最终一致 (听binlog的总没错).- 数据无价, 谨慎操作.
本文发布于朴瑞卿的博客, 允许非商业用途转载, 但转载必须保留原作者朴瑞卿 及链接:http://blog.piaoruiqing.com. 如有授权方面的协商或合作, 请联系邮箱: piaoruiqing@gmail.com.