Redis之管道的使用
原文地址: https://blog.piaoruiqing.com/blog/2019/06/24/redis管道
关键词 Redis Pipelining: 客户端可以向服务器发送多个请求而无需等待回复, 最后只需一步即可读取回复.
RTT(Round Trip Time): 往返时间.
为什么要用管道 Redis是使用client-server 模型和Request/Response 协议的TCP服务器. 这意味着通常通过以下步骤完成请求:
客户端向服务器发送查询, 并通常以阻塞方式从套接字读取服务器响应.
服务器处理该命令并将响应发送回客户端.
应用程序与Redis通过网络进行连接, 可能非常快(本地回环), 也可能很慢. 但无论网络延迟是多少, 数据包都需要时间从客户端传输到服务器, 然后从服务器返回到客户端以进行回复(此时间称为RTT). 当客户端需要连续执行许多请求时(例如, 将多个元素添加到同一列表或使用多个键填充数据库), 很容易发现这种频繁操作很影响性能. 使用管道将多次操作通过一次IO发送给Redis服务器, 然后一次性获取每一条指令的结果, 以减少网络上的开销.
频繁操作但未使用管道的情形如下图:
1 2 3 4 5 6 7 8 9 10 11 12 13 sequenceDiagram participant client participant server client ->> +server: Note over client,server: set mykey1 myvalue1 server -->> -client: OK client ->> +server: Note over client,server: set mykey1 myvalue1 server -->> -client: OK client ->> +server: Note over client,server: ... server -->> -client: OK
使用管道后如下图:
1 2 3 4 5 6 7 sequenceDiagram participant client participant server client ->> +server: Note over client,server: set mykey1 myvalue1 <br/> set mykey2 myvalue2 <br/>... server -->> -client: OK, OK, OK ...
如何使用 Jedis 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 private final Logger LOGGER = LoggerFactory.getLogger(getClass());private static final JedisPool POOL = new JedisPool(new JedisPoolConfig(), "test-redis-server" , 6379 ); @Test public void testPipelining () try (Jedis jedis = POOL.getResource()) { Pipeline pipelined = jedis.pipelined(); Response<String> response1 = pipelined.set("mykey1" , "myvalue1" ); Response<String> response2 = pipelined.set("mykey2" , "myvalue2" ); Response<String> response3 = pipelined.set("mykey3" , "myvalue3" ); pipelined.sync(); LOGGER.info("cmd: SET mykey1 myvalue1, result: {}" , response1.get()); LOGGER.info("cmd: SET mykey2 myvalue2, result: {}" , response2.get()); LOGGER.info("cmd: SET mykey3 myvalue3, result: {}" , response3.get()); } }
(一): jedis.pipelined(): 获取一个Pipeline用以批量执行指令.
(二): pipelined.sync(): 同步执行, 通过读取全部Response来同步管道, 这个操作会关闭管道.
(三): response1.get(): 获取执行结果. 注意: 在执行pipelined.sync()之前, get是无法获取到结果的.
Lettuce 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 private final Logger LOGGER = LoggerFactory.getLogger(getClass()); private static final RedisClient CLIENT = RedisClient.create("redis://@test-redis-server:6379/0" ); @Test public void testPipelining () throws ExecutionException, InterruptedException try (StatefulRedisConnection<String, String> connection = CLIENT.connect()) { RedisAsyncCommands<String, String> async = connection.async(); async.setAutoFlushCommands(false ); RedisFuture<String> future1 = async.set("mykey1" , "myvalue1" ); RedisFuture<String> future2 = async.set("mykey2" , "myvalue2" ); RedisFuture<String> future3 = async.set("mykey3" , "myvalue3" ); async.flushCommands(); LOGGER.info("cmd: SET mykey1 myvalue1, result: {}" , future1.get()); LOGGER.info("cmd: SET mykey2 myvalue2, result: {}" , future1.get()); LOGGER.info("cmd: SET mykey3 myvalue3, result: {}" , future1.get()); } }
RedisTemplate 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 private final Logger LOGGER = LoggerFactory.getLogger(getClass());@Resource private StringRedisTemplate stringRedisTemplate;@Test public void testPipelining () List<Object> objects = stringRedisTemplate.executePipelined((RedisCallback<Object>)connection -> { connection.set("mykey1" .getBytes(), "myvalue1" .getBytes()); connection.set("mykey2" .getBytes(), "myvalue2" .getBytes()); connection.set("mykey3" .getBytes(), "myvalue3" .getBytes()); return null ; }); LOGGER.info("cmd: SET mykey myvalue, result: {}" , objects); }
简单对比测试
redis服务器运行在同一个路由器下的树莓派上.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 @Test public void compared () try (Jedis jedis = POOL.getResource()) { jedis.set("mykey" , "myvalue" ); } try (Jedis jedis = POOL.getResource()) { long start = System.nanoTime(); Pipeline pipelined = jedis.pipelined(); for (int index = 0 ; index < 500 ; index++) { pipelined.set("mykey" + index, "myvalue" + index); } pipelined.sync(); long end = System.nanoTime(); LOGGER.info("pipeline cost: {} ns" , end - start); } try (Jedis jedis = POOL.getResource()) { long start = System.nanoTime(); for (int index = 0 ; index < 500 ; index++) { jedis.set("mykey" + index, "myvalue" + index); } long end = System.nanoTime(); LOGGER.info("direct cost: {} ns" , end - start); } }
使用Jedis执行500条set, 执行结果如下:
1 2 22:16:00.523 [main] INFO - pipeline cost: 73681257 ns // 管道 22:16:03.040 [main] INFO - direct cost : 2511915103 ns // 直接执行
500次set执行时间总和已经和管道执行一次的所消耗的时间不在一个量级上了.
扩展
摘自redis官方文档
使用管道不仅仅是为了降低RTT以减少延迟成本, 实际上使用管道也能大大提高Redis服务器中每秒可执行的总操作量. 这是因为, 在不使用管道的情况下, 尽管操作单个命令开起来十分简单, 但实际上这种频繁的I/O操作造成的消耗是巨大的, 这涉及到系统读写的调用, 这意味着从用户域到内核域.上下文切换会对速度产生极大的损耗.
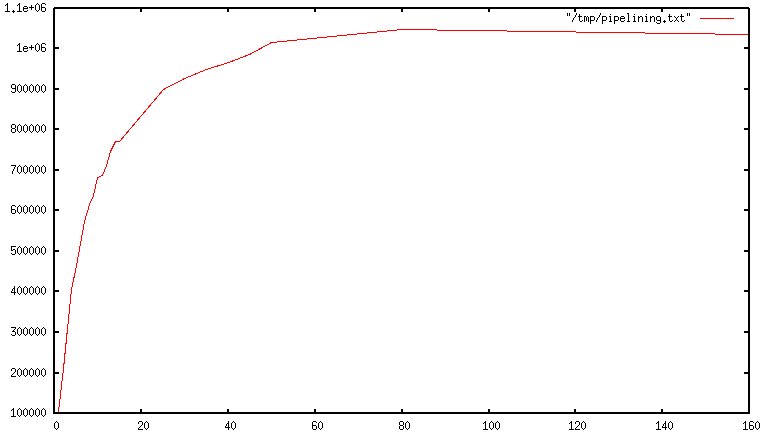
使用管道操作时, 通常使用单个read() 系统调用读取许多命令,并通过单个write()系统调用传递多个回复. 因此, 每秒执行的总查询数最初会随着较长的管道线性增加, 并最终达到不使用管道技术获的10倍, 如下图所示:
参考文献
欢迎关注公众号(代码如诗):